引言
基础模型:hidream l1 full
hidream l1 与 flux.1 结构类似但是又有所不同。
文本编码器
hidream l1 文本编码器包括
clip_l,clip_g,t5xxl,llama3.1_8b_instruct
前三与 stable-diffusion-3 是一样的。值得注意的是 llama3.1_8b。
个人猜测 之所以使用 llama3.1_8b 是因为其能更好的理解自然语言提示。值得注意的是,后续输入到DiT
的部分并非llama3.1_8b_instruct的后续输出。而是 prefill 过程中产生的隐藏状态(kv cache)。也就是说 hidream l1 利用到了 llama3.1_8b_instruct 对于文本的理解。这点在我们后续 caption 的需要用到。
去噪模型
相较与传统的模型,hidream l1 使用的是基于 Transformer 的 HiDreamImageTransformer2DModel。因此可以较好的融合 llama3.1_8b_instruct 的隐藏状态。HiDreamImageTransformer2DModel 相关这里篇幅有限不再追溯。
VAE
使用了 Flux 的 VAE。这里也不在展开。
训练角色
娜娜奇(日语:ナナチ Nanachi) 《来自深渊》中的主要角色之一,拥有毛茸茸的奇特外表加上较为罕见因此被选为本次实验对象。

在没有训练之前模型只知道娜娜奇是兔子?个人猜测是因为几个文本编码器训练时有娜娜奇的语料。而hidream l1 训练过程中并没有。因此文本编码器给出了类似兔子的向量编码。
实验:
提问Llama-3.1-8B-Instruct :”what is Nanachi?“
回答Nanachi is a fictional character from the manga and anime series "Dead Dead Demon's Dededededestruction" by Inio Asano. Nanachi is a tanuki (a type of Japanese raccoon dog) who becomes a companion to the main character, Akira Tachibana.
However, it seems you might be referring to Nanachi from another context. After further consideration, I found that Nanachi is also a character from the anime and manga series "Made in Abyss." In this series, Nanachi is a small, raccoon-like creature who befriends the main character, Riko. Nanachi has the ability to heal and communicate with humans.

图为没训练过的模型生成的娜娜奇
hidream l1 full 与 dev 与 fast
我们训练需要使用hidream l1 full 而不是 hidream l1 dev 与 hidream l1 fast
原因是 hidream l1 dev 与 hidream l1 fast 是蒸馏模型。我们微调使用的是传统的训练方式,与 hidream l1 full 的训练过程相似。因此我们使用 hidream l1 full
### 硬件
博主这次的硬件上 RTX 4090 24G
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.86.10 Driver Version: 570.86.10 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:01:00.0 On | Off |
| 0% 43C P8 23W / 450W | 410MiB / 24564MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
因此我们需要采用量化的方法进行 lora 的训练。这个我们在后续会提到训练
配置环境
我这里选择的框架上 diffusion-pipe 。安装过程按照 GitHub 上的 Installing 来。
在你知道自己在做什么时,你也可以不按照上面👆的来。比如我就不喜欢使用 conda 。 而是通过通过 apt 安装 nvcc。 venv 创建虚拟环境。
环境上有两坑。一个是 pytorch 的 pip 国内源(上交大,阿里)的 cu128 目前(2025年4月28日)是无法使用的。要不就开代理使用官方源,要不就用 cu126 等较低版本。
另外一个坑是 fast attention 的。安装 fast attention 没有构建好的 whl 。只能本地编译。网上有人说 fast attention 在较久的版本(pytorch 的? cuda 的?)有构建好的。但我没找到过。编译过程十分缓慢痛苦。推荐安装 ninja 。并确保正常。否则编译时长可能超过 2小时。可以参考 https://github.com/Dao-AILab/flash-attention#:~:text=*%20Make%20sure%20that,using%20CUDA%20toolkit.
数据集
个人认为这是深度学习最痛苦的地方。也是耗费我大量精力虽然只有 30 张娜娜奇的图片。请记住,输入垃圾,输出垃圾。数据要求质量大于数量。同时也要考虑,hidream l1 full 是通才模型。多样性可以降低模型崩坏的可能。

通过搜索引擎,和在某飞机上搜集了30张不同角度的娜娜奇。后通过视觉模型打上 caption (不推荐,建议手动打,除非你和我一样忙(lang),这里附上提示词)。
PROMPT = 'Add a description to the image. Include the background, character actions, surroundings, colors, atmosphere, and style, but do not include the character\'s appearance or clothing. The character must be referred to as "nnq". The description should start with "A drawing of nnq". The description should < 128 tokens'你可以手动完成,也可以自己写一个脚本。视觉模型打标花了我 0.1 美刀(其实是白嫖的)。
结果应该是这样的,一个对应的图片对应相同名称的 txt 文本文件
训练配置文件
在此配置下 4090 24G 的显存恰好吃满。
type = 'hidream'
diffusers_path = '/home/<wsl_username>/workspace/models/hidream-full'
llama3_path = '/home/<wsl_username>/workspace/models/llama-3.1'
llama3_4bit = true
dtype = 'bfloat16'
transformer_dtype = 'nf4'
max_llama3_sequence_length = 128
flux_shift = true这里的 llama3 采用 4 bit 量化。
而 diffusers 部分采用 nf4 量化。
而我们需要训练的 lora 部分是不会量化的。
训练过程
NCCL_P2P_DISABLE="1" NCCL_IB_DISABLE="1" deepspeed --num_gpus=1 train.py --deepspeed --config config.toml训练需要时间 4090 2个多小时。训练了 60 epoch。
tensorboard --logdir '<输出路径>diffusion-pipe/workspace/output'
可以看到训练过程
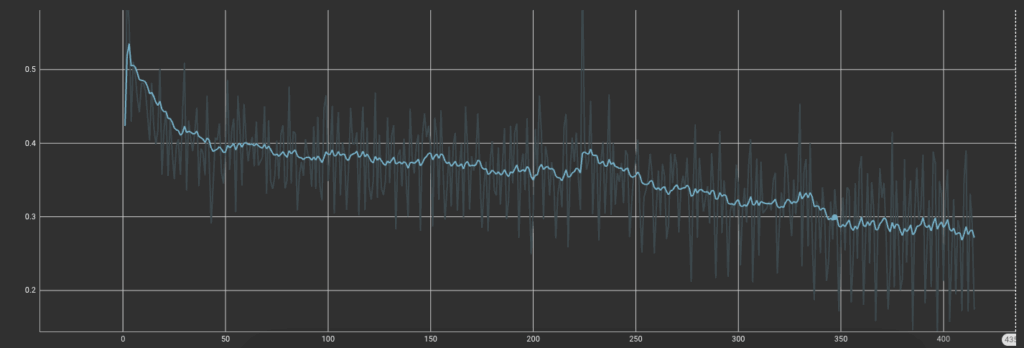
看到 loss 差不多停止下降后。ctrl + c 停止训练
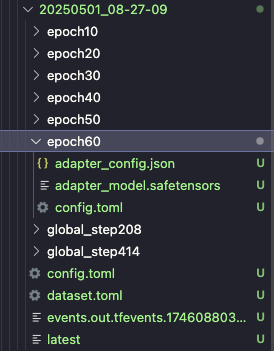
epoch 60 处的 safetensors 文件就是我们最终的 lora 模型。
评估
导入模型到 comfyui.
提示词:
A drawing of nnq with detailed background, A park with wisteria flowers in bloom, wisteria flowers in full bloom, a faint glimpse of the sky.nnq half lying on the grass
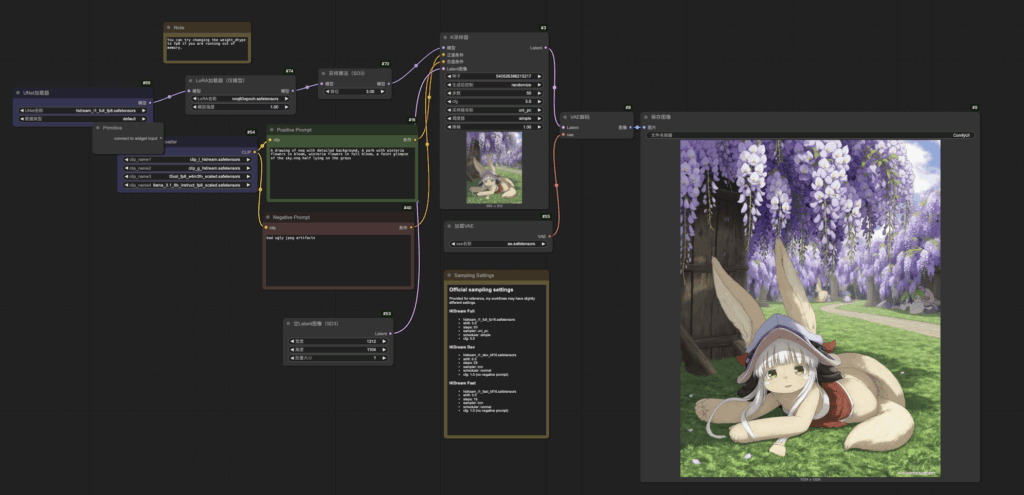

提示词需要对应上微调过程中的 caption .
就是以 A drawing of nnq 开头加上 nnq 位置动作描述。否则...
not ”A drawing of nnq“ 就不是 娜娜奇 了

没有描述 nnq 位置动作描述。就没有娜娜奇 也能出。

Comments NOTHING